![banner]()
![Orion-14B]()
法人向け、革新的な生成AI
法人向け、革新的な生成AI
手が届く、実用的、安心なLLM
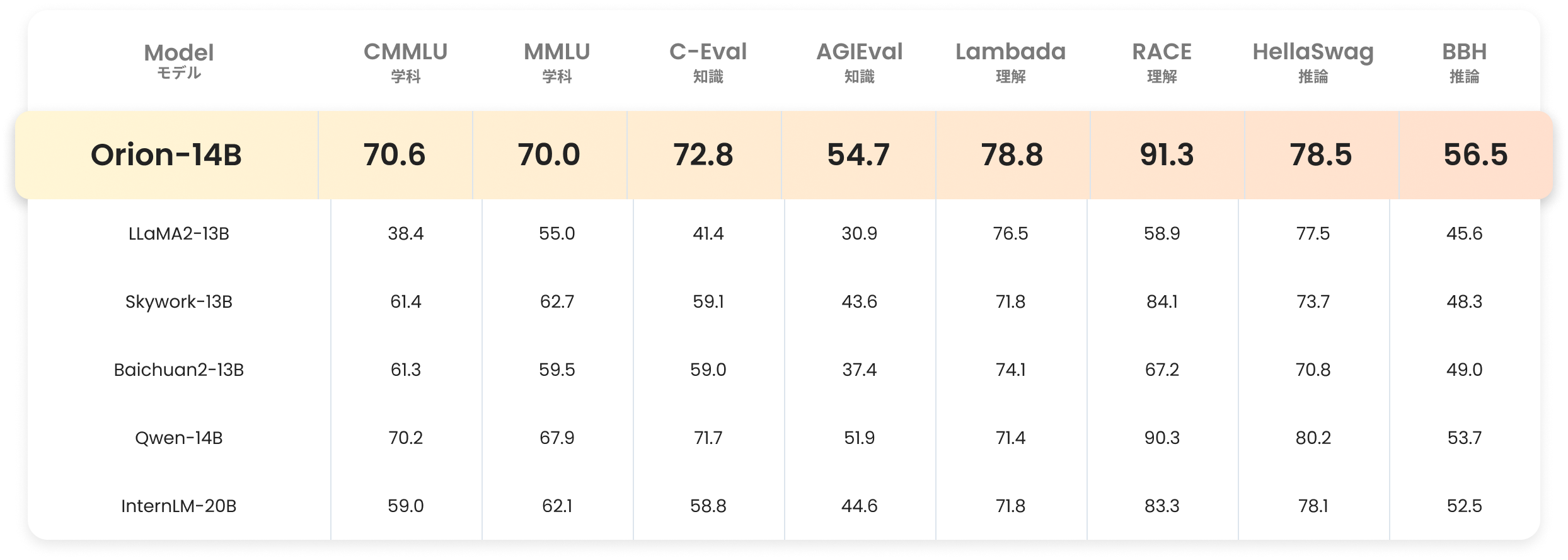
評価指標
![猎户星空大模型,Orion-14B评测指标]()
第三者機関OpenCompassによる独立評価結果
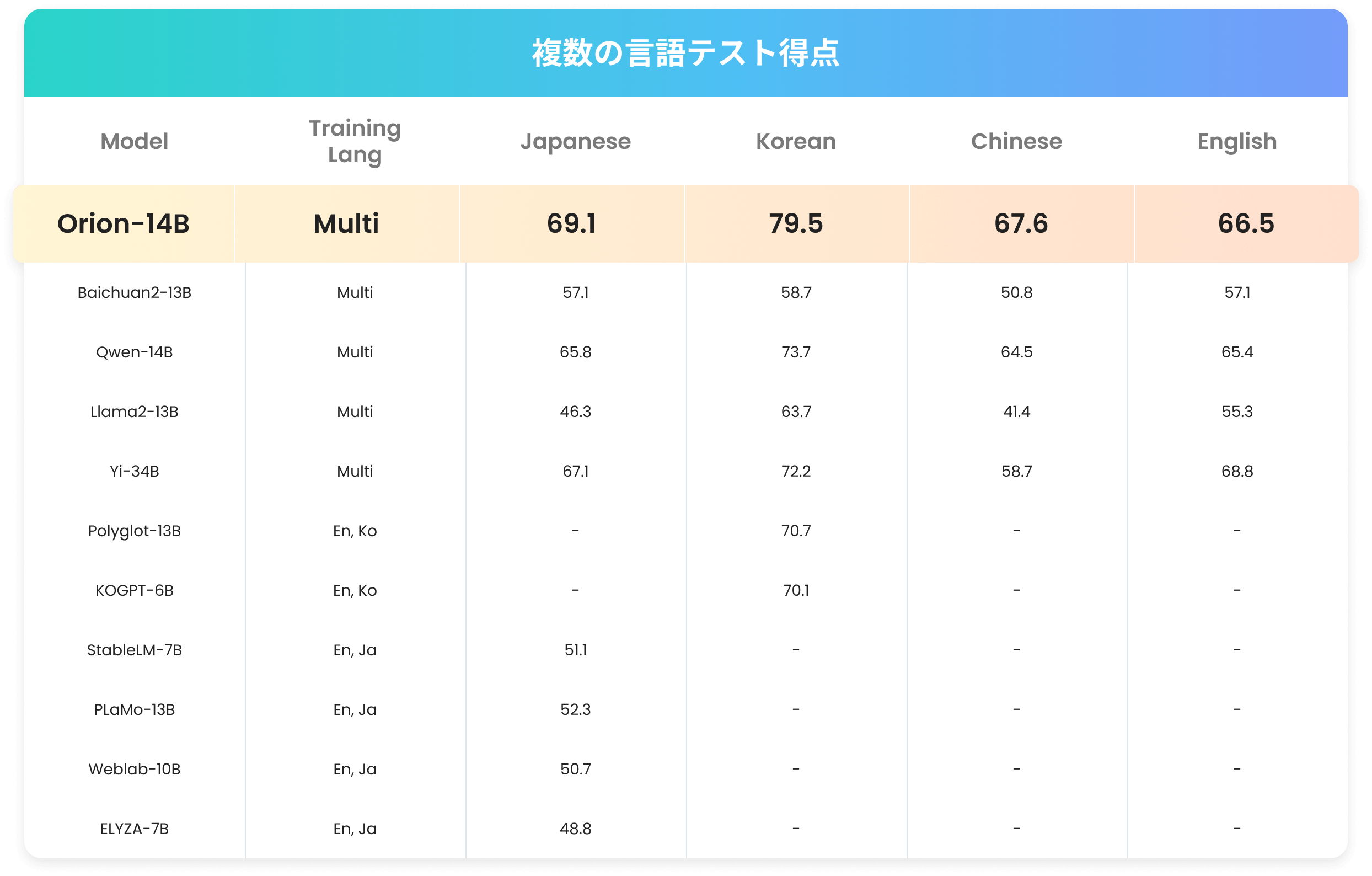
複数の言語テスト得点
![猎户星空大模型,Orion-14B评测指标]()
性能特徴
100億規模モデルでSOTA
14Bパラメータの中規模モデルであり、全体的なパフォーマンスは20B未満モデルのSOTA評価に達しています
320K超長文対応
32万トークンの超長テキストを一度に受け入れ、正確にキーワード情報を抽出できます
企業向け最善の選択肢
- ファインチューニングモデルは適応性高い
- INT4量子化されても性能損失が1%以下
優れた多言語力
中文、英語、日本語、韓国語の評価において、20B以下のパラメータモデルで1位となります。
技術的な優位性
![研究開発能力]()
研究開発能力
開発チームは、Facebook、Yahoo、百度など、世界トップクラスのアルゴリズム科学者が集まっています。
![アルゴリズム能力]()
アルゴリズム能力
DNN、アテンション、BertからLLM、ASR、TTS、NLPまでの技術路線は、産業の技術進化を追跡しています。
![需要理解と分析]()
需要理解と分析
数千の企業から異なるシーンの要求を深く理解でき、経験の積み重ね、操作性に富んでいます。
![実用性を磨き]()
実用性を磨き
20億以上のグローバルユーザーに対する、データフィードバックを蓄積し、よりニーズに即したものにしています。
![データの蓄積]()
データの蓄積
7年間のAIデータの蓄積で、数十億の実際のクエリと数兆のトークンデータを取り扱っています。
活用性が優れた企業向け生成式AIモデル
ファインチューニングシリーズ:専門分野の分別対応、100億規模モデルでのSOTA、1000億規模モデルに迫る処理能力
![チャット]()
チャット
20B以下高品質な対話型モデルで、より良いユーザーインタラクション体験を提供します。
![プラグイン]()
プラグイン
プラグインと関数呼び出しタスクに特化し、エージェント、リアクト、プロンプティング能力の強化です。
![RAG]()
RAG
スタムの検索強化より,回答の精度、1000億規模のモデルに近い効果を実現しています。
![長文対応]()
長文対応
20万トークンの長さで優れた効果を発揮し、最大で320,000トークンまでサポートできます。
![知識抽出]()
知識抽出
既存の知識ベースから情報抽出し、特定のタスクやドメインに適合するようにします
![質問応答生成]()
質問応答生成
既存の質問と回答のデータを使用し、回答の品質と正確性を向上させます。
![日韓文強化]()
日韓文強化
日本語と韓国語のテキストデータでトレーニング、20B以下得点1位です。
Orion-14B生成AIモデル
手軽に利用でき法人向け生成AI
![ビジネスに適した軽量化]()
ビジネスに適した軽量化
INT4量子化後、モデルサイズは70%減少し、推論速度は30%向上でき、性能の損失はわずか1%未満です。
![ミッドレンジグラフィックスカードで稼働でき]()
ミッドレンジグラフィックスカードで稼働でき
NVIDIA RTX 3060では、毎秒31トークン、約50文字を処理可能です。
![<span>手軽に利用でき</span>法人向け生成AI]()
手軽に利用でき法人向け生成AI
![ビジネスに適した軽量化]()
ビジネスに適した軽量化
INT4量子化後、モデルサイズは70%減少し、推論速度は30%向上でき、性能の損失はわずか1%未満です。
![ミッドレンジグラフィックスカードで稼働でき]()
ミッドレンジグラフィックスカードで稼働でき
NVIDIA RTX 3060では、毎秒31トークン、約50文字を処理可能です。
![<span>手軽に利用でき</span>法人向け生成AI]()
セキュリティに配慮企業内部で活用できます
![プライベート環境での展開可能]()
プライベート環境での展開可能
サーバーは企業の内部ネットワークに配置され、すべてのデータは公共のインターネットに接続されることはありません。
![無料でオープンソースであり、商業利用もOK]()
無料でオープンソースであり、商業利用もOK
コミュニティによる技術サポートがあります。Hugging Face、ModelScope、GitHubからまず試してください。
![<span>セキュリティに配慮</span>企業内部で活用できます]()